-
[테코톡] DB Index 2, MySQL 인덱스와 실행계획DB/DB 2023. 5. 20. 17:51
---
https://youtu.be/nvnl9YgnON8 - 매트토르, MySQL 최적화
---

왜 쓸까 성능 개선을 위해 인덱스를 건다
어떻게 쓸까 어디에 인덱스를 어떻게 걸어야할지 고민일 것이다 사례위주로
쿼리 최적화 중에서도 인덱스를 활용한 쿼리 최적화에 집중
MySQL 8.0, InnoDB
---
발표에서 사용할 테이블

crew - track이 백엔드, 프론트엔드
study_log
---
인덱스를 왜 쓸까?
DB에서 성능 최적화는 디스크 I/O와 관련이 많다.

하드디스크에서 원하는 곳에 있는 데이터를 읽기 위해 실제로 디스크가 돌아야 되고, 저 바늘처럼 보이는 헤더가 움직여야 한다. 이 과정에서 물리적 움직임이 있기 때문에 데이터의 입출력이 느리다.
하드디스크 IO와 메모리 IO의 속도 차이는 10만~15만 배 정도. 달팽이와 전투기의 속도 차이
SSD가 많이 보편화됐지만 그래도 여전히 메모리 IO에 비해서는 많이 느리다
성능개선을 한다고 하는 것은, 디스크 IO를 줄이는 것이 핵심이다.
---
INDEX는 R은 빨라지고 CUD는 느려진다

상위권에 있는 API들이 전부 GET요청이기 때문에 조회에서 성능최적화를 하고 CUD는 좀 손해를 봐도 전체적으로 이득이다.
---
ORDER BY, GROUP BY에서도 이득을 얻을 수 있다.

---

nickname에 의해 order by 즉 정렬을 하고 있는데, 인덱스가 없었다면 데이터를 다 읽어와서 DB에서 직접 정렬했어야 할 것. 하지만 인덱스는 이미 정렬돼 있기 때문에 인덱스 순서대로 파일을 읽기만 하면 된다.
---
GROUP BY도 비슷한데

각 track에서 nickname이 가장 빠른 사람들을 가져오는 쿼리를 날린다고 하면 ▽MIN(nickname)
인덱스가 걸려 있는 경우엔 저 꼬재를 읽고, 나머지 데이터를 읽지 않고 바로 backend track으로 넘어가서 '매트'만 읽으면 된다.
중간을 읽지 않았기 때문에 디스크 IO를 많이 줄일 수 있다
---
실행계획
여러가지가 있는데 가장 중요하고 많이 나오는 것 3가지만

---
all = Full Table Scan
데이터를 하나하나 다 읽는 것
디스크 IO는 시간이 많이 걸리는 작업이기 때문에 Full Table Scan을 타면 성능이 좋지 않다

FTS가 일어나는 2가지 경우
(1)index가 없어서
(2)index가 있는데도 -> 데이터 전체의 개수가 그렇게 많지 않거나, 읽고자 하는 데이터가 전체 데이터의 25%를 넘어가면 index가 있다 하더라도 FTS가 일어남
---
Range Scan
이상적으로 index를 잘 걸었을 때 발생하는 실행 계획

예를 들어, id가 19이상, 27이하인 데이터를 가져오라고 했을 때
Root에서부터 타고 내려간다
19가 17보다 크니까 오른쪽
24보다 작으니 왼쪽
위의 FTS에서 다 읽었던 것과 달리 필요한 부분만 읽게 됨
탐색할 데이터를 줄이기 때문에 디스크 IO를 줄일 수 있다
---
index = Index Full Scan. 전체 인덱스를 다 읽게 되는 것

FTS보다는 물론 성능이 좋다(전체 데이터의 25%이하를 조회할 때). 인덱스는 데이터 파일 보다는 크기가 작으니까.
Index Range Scan보다는 성능이 좋지 않다
---
적용 사례 (1)기본 컬럼에 인덱스 적용
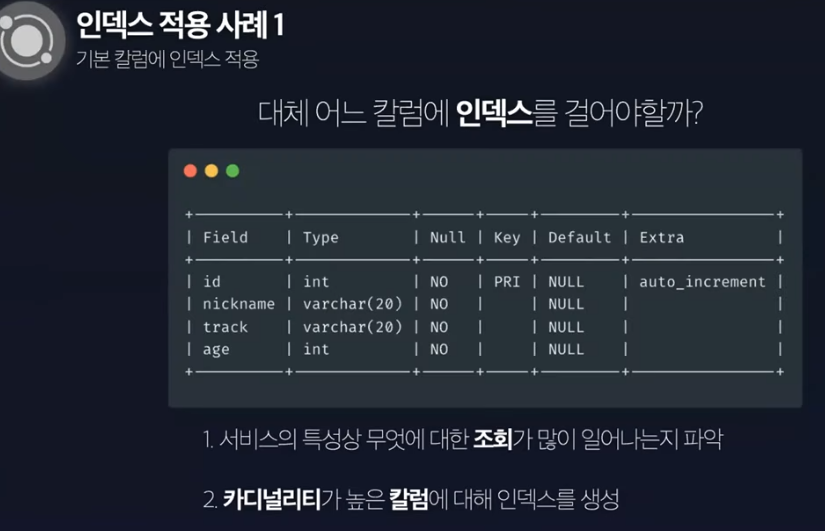
이렇게 돼 있을 때 index를 어떻게 걸어야 할지 고민한다.
id의 경우엔 innoDB니까 클러스터드 인덱스가 미리 걸려있어
그럼 이제 nickname, track, age가 있는데
인덱스를 걸기 위해선 서비스의 특성상 무엇에 대한 조회가 많이 일어나는지를 우선 파악해야해
예를 들어 nickname에 대한 조회가 많다고 가정한다.
그 다음엔 카디널리티를 따짐. 높은 컬럼에 대해 인덱스를 생성.
track은 백/프 뿐. nickname은 중복 안됨
그래서 nickname에 인덱스를 건다

처음에 실행계획이 ALL(FTS)였다가, 인덱스를 걸고나니 range(IRS)로 바뀐 것을 볼 수 있다 ▽실행계획만 조회해서 바뀌면 좋은건가보네?

실제 성능도 좋아짐
---
적용 사례 (2)복합 인덱스 적용

▽더 적은 데이터 분포란, 정렬을 하고 거기서도 또 다른걸로 정렬을 해놔서, select할 때 그 컬럼 두개로 찾으면 편하다는 걸로 이해가 되는데
이게 어떻게 쓰이냐면

이 테이블은 age순, 그 다음에는 nickname순으로 정렬돼 있다.
이렇게 정렬된 기준을 통해서 이 쿼리를 날렸을 때,
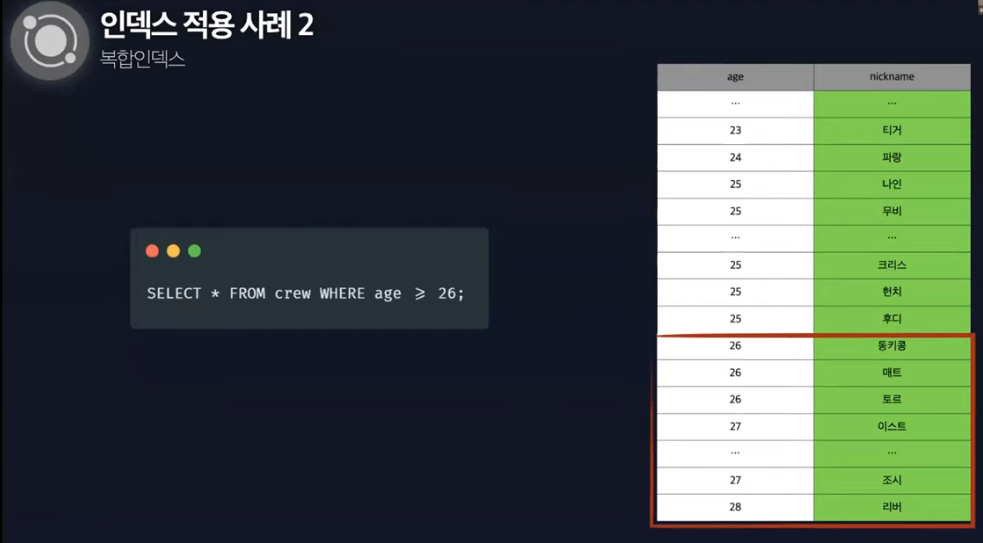
(탐색 범위를 줄일 수 있을까?생각해보면 복합인덱스를 쓸 수 있을지 없을지 알 수 있다.)
일단 이건 26부터 찾으면 되니까 탐색범위를 줄일 수 있다. 이 정렬 기준을 이용해서 데이터 탐색 범위를 줄였다.
---
26이상, 토르보다 닉네임이 뒤에 나오는 사람들을 가져올 때, 여기서 토르 이후인 사람들을 가져오면 되기 때문에 탐색 범위가 줄어들었다

---
nickname을 기준으로 탐색하고자 하면?

nickname이 동키콩 이후인 사람들은 티거, 파랑, 조시, 리버... 이다
이 정렬 기준으로는 우리가 원하는 만큼 탐색 범위를 줄일 수 없다.
따라서 FTS를 하게 된다. 디스크 IO를 줄일 수 없다.
이런 것들을 잘 고려해서 복합 인덱스를 사용한다
---
인덱스 적용 사례 (3)커버링인덱스
인덱스를 사용하여 처리하는 쿼리 중에 가장 큰 부하를 차지하는 부분은
인덱스 검색에서 일치하는 키 값의 레코드를 읽는 것이다.


▽논클러스티드 인덱스인데.. 이해 안감.. 디스크 IO는 메모리에 없기 때문에 디스크에 다녀온다는 얘기고, 여기 강의에서는 탐색 범위를 줄여야 하는데 늘어난다 느낌으로 설명하고 있는 것 같은데. 인덱스로 줄여놨지만 여전히 많다 이런 느낌이야? 아래 한번 쭉 보자 -> 뒤에 내용 보니까, 리프 노드가 nickname, track 두개로 돼 있다. 그리고 그 다음에 또 데이터 파일을 읽으러 가
쿼리 최적화 하려면 디스크IO 줄여야 해
---
간단한 예시


원활한 조회를 위해 복합 인덱스 추가
이러면 실행계획은, FTS가 발생

▽저 SELECT는 많은 데이터를 조회하기 때문에 그냥 바로 읽는게 낫다고 생각해서 이렇게 된 것 이라는 설명인듯
이것을 커버링 인덱스를 통해 개선할 수 있다

---
맞춰서 쿼리를 개선해보면
모든 컬럼을 조회하던 쿼리에서, 인덱스에 대한 쿼리 조회로 개선을 한거야.

이렇게 하면

데이터 파일을 읽지 않는구나!! 이제 이해가 되네. 그리고 쿼리를 고치는 거구나, 인덱스 설정을 만지는게 아니라
실행 계획 보면

type에 IRS
Extra에 Using index가 표시

모든 쿼리를 조회 = 커버링 인덱스를 타지 않음
nickname, track만 조회 = 커버링 인덱스를 탐
이 두개의 차이구나, select문을 바꾼거고, 훨씬 빨라짐
---
커버링 인덱스의 비밀, PK를 같이 조회하는 쿼리라면?

이전과 동일하게 커버링 인덱스를 활용한다

이건 나도 알고 있지 리프노드에 PK가 같이 써있으니까

그래서 셋다 모두 커버링 인덱스로 활용이 가능하다~!
▽InnoDB의 특징이군요 이게
---
인덱스 적용 사례 (4)인덱스 컨디션 푸시다운

study_log 테이블에 type이라는 컬럼은 share, question등 study log의 목적을 명시
비즈니스 로직상 type을 기준으로 조회가 많이 일어난다고 가정하고, 인덱스를 생성함.
---
간단한 예시

type은 question
10월 7일부터 10월 13일 사이 학습로그를 조회하는 쿼리
---
실행계획을 보면

방금 생성한 index가 key값으로 잘 활용이 돼서 인덱스를 탔다
언뜻보면 인덱스가 잘 적용된 것 같지만??

Extra컬럼의 Using where이라는게 보여


---
뭔소리냐면
그림으로 살펴보면

type을 기반으로 생성된 index를 통해
InnoDB 스토리지 엔진이 조건을 활용해서 인덱스 필터링을 거치고
디스크 파일에서 500612개의 데이터를 MySQL 엔진으로 전달
MySQL엔진은 인덱스로 걸지 않은 생성일을 기반으로 체크 조건을 통해 9061개 데이터를 필터링해서 사용자에게 전달한다.
현재 InnoDB 스토리지 엔진은 불필요하게 너무 많은 데이터를 디스크에서 읽는다
---
이걸 복합 인덱스를 통해 개선이 가능하다.

이 두개로 복합 인덱스를 생성하고
실행계획을 보면

방금 생성한 복합 인덱스를 key로 잘 활용해서 IRS가 발동
---
추가적으로

얜 뭐냐면

WHERE조건 부분을 모두 스토리지 엔진으로 푸시
ICP는 최신 버전의 MySQL이면 기본 활성화 돼 있는 옵션
---

다시 그림을 살펴보면 InnoDB 스토리지 엔진이 복합 인덱스로 설정된 type과 created_at을 모두 인덱스 조건으로 활용해서 디스크에서 오직 9061개 데이터만 읽어서 MySQL엔진으로 전달!
MySQL엔진은 추가적인 필터링 과정 없이 그대로 9061개 데이터를 사용자에게 전달
=>불필요한 디스크 IO를 줄였다
---

실행계획을 판단할 때, 단순히 type만 보고 이 실행 계획이 인덱스를 탔다, 안탔다 판단 하는것보다
Extra 컬럼까지 함께 고려해서 인덱스가 적절히 탔는지 보자
---
여기까지 인덱스와 실행계획을 봤는데, 이것도 작은 부분이라

이런 것들을 더
---

'DB > DB' 카테고리의 다른 글
[테코톡] Deadlock (0) 2023.05.22 [테코톡] DB Lock (0) 2023.05.22 [테코톡] DB Index 1 (0) 2023.05.18 [테코톡] DB Replication 3, Clustering, Sharding (0) 2023.03.10 [테코톡] DB Replication 2 (0) 2023.03.08