-
[테코톡] DB Replication 1, GTID, Statement&RowDB/DB 2023. 3. 7. 20:58
---
https://youtu.be/NPVJQz_YF2A - 엔지, 자막
https://youtu.be/95bnLnIxyWI - 영이, 자막
https://youtu.be/y42TXZKFfqQ - 히브리 클러스터링 샤딩 레플리케이션
---
https://youtu.be/NPVJQz_YF2A - 엔지의 DB Replication - 참고 Real MySQL 8.0 (하)
DB Replication
DB Replication 과정
DB Replication topology
복제 과정 중 문제 발생 시 회복 기법
MySQL 8.0버전, InnoDB 기준
---
(1)
DB Replication
데이터 베이스를 복제하는 행위
하나 있는 데이터베이스를 잘 쓰면 되는거 아냐? 왜 여러개 둬?

또

스케일업하면 되겠지만 스케일업에도 한계가 있다
데이터베이스 레플리케이션 구조 잠깐

Source서버 : 원본 데이터를 가진 DB 서버
Replica서버 : 복제된 데이터를 가지고 있는 DB 서버
소스-레플리카 구조 : 소스서버에서 데이터 변경이 일어나면 변경된 내용이 레플리카 서버에도 동일하게 반영된다
Case 1(망가짐)의 경우 소스서버에 문제가 생기면 레플리카 서버를 소스서버로 승격시켜 사용할 수 있다.

이러면
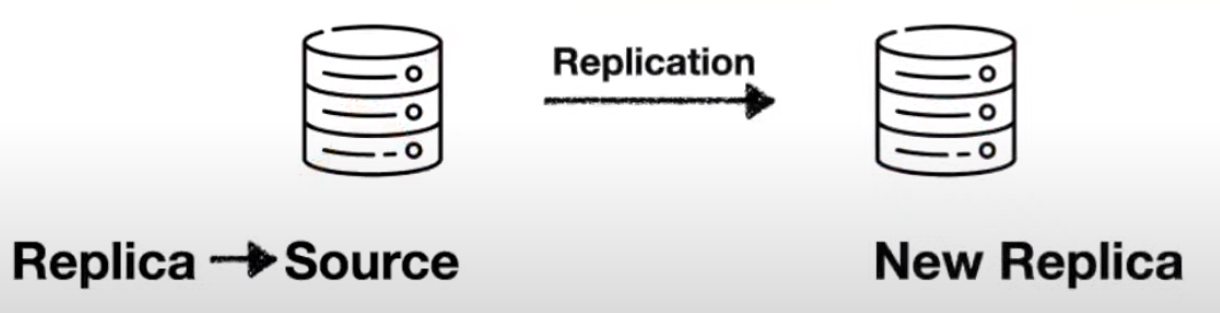
Case 2(부하)의 경우 소스서버를 Write DB로, 레플리카 서버를 읽기 전용인 Read DB로 사용해 부하를 해결할 수 있다.(해결책 write-read db 분리)

---
(2)
DB Replication 과정

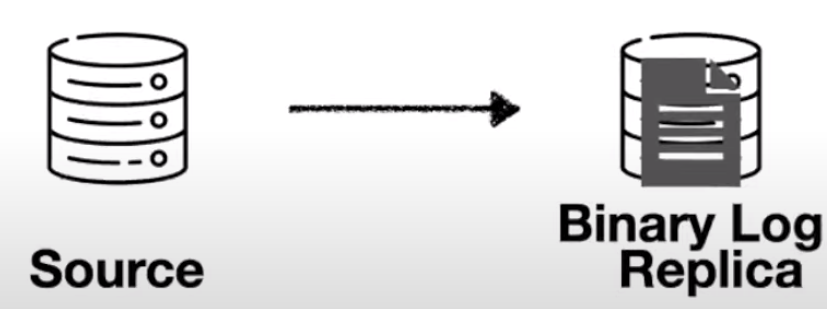
복제는 소스서버의 바이너리 로그를 기반으로 일어난다.
바이너리 로그는 저거고
즉 소스서버에 변경이 일어나서 바이너리 로그 이벤트가 기록되면 이 이벤트는 레플리카 서버가 자신의 로컬 디스크에 저장한 뒤 이 이벤트를 읽어서 자신의 데이터 파일에 반영
자세하게는

이 복제에 총 세가지 쓰레드가 사용되고 있는데,
먼저 소스서버에 바이너리 로그의 이벤트가 변경이 일어나면
1)바이너리 로그 덤프 쓰레드가 이 이벤트를 읽어서 레플리카 서버로 전송.
2)레플리카 서버의 I/O쓰레드는 이 변경 이벤트를 자신의 로컬파일인 릴레이 로그에 저장

아직 레플리카 서버에는 데이터의 변경이 반영되지 않았는데, 이를 반영하기 위해 3)SQL 쓰레드가 변경 내용을 데이터 파일에 저장한다.

---
복제의 타입

레플리카 서버는 소스 서버의 바이너리 로그이벤트를 어떻게 식별하여 반영할까? 2가지 방식이 있다

먼저 바이너리 로그 파일 위치 기반 복제 방식

소스서버 바이너리 로그의 로그 파일명과 오프셋을 이용해 식별
소스서버에서만 유용한 식별 방법
??어??

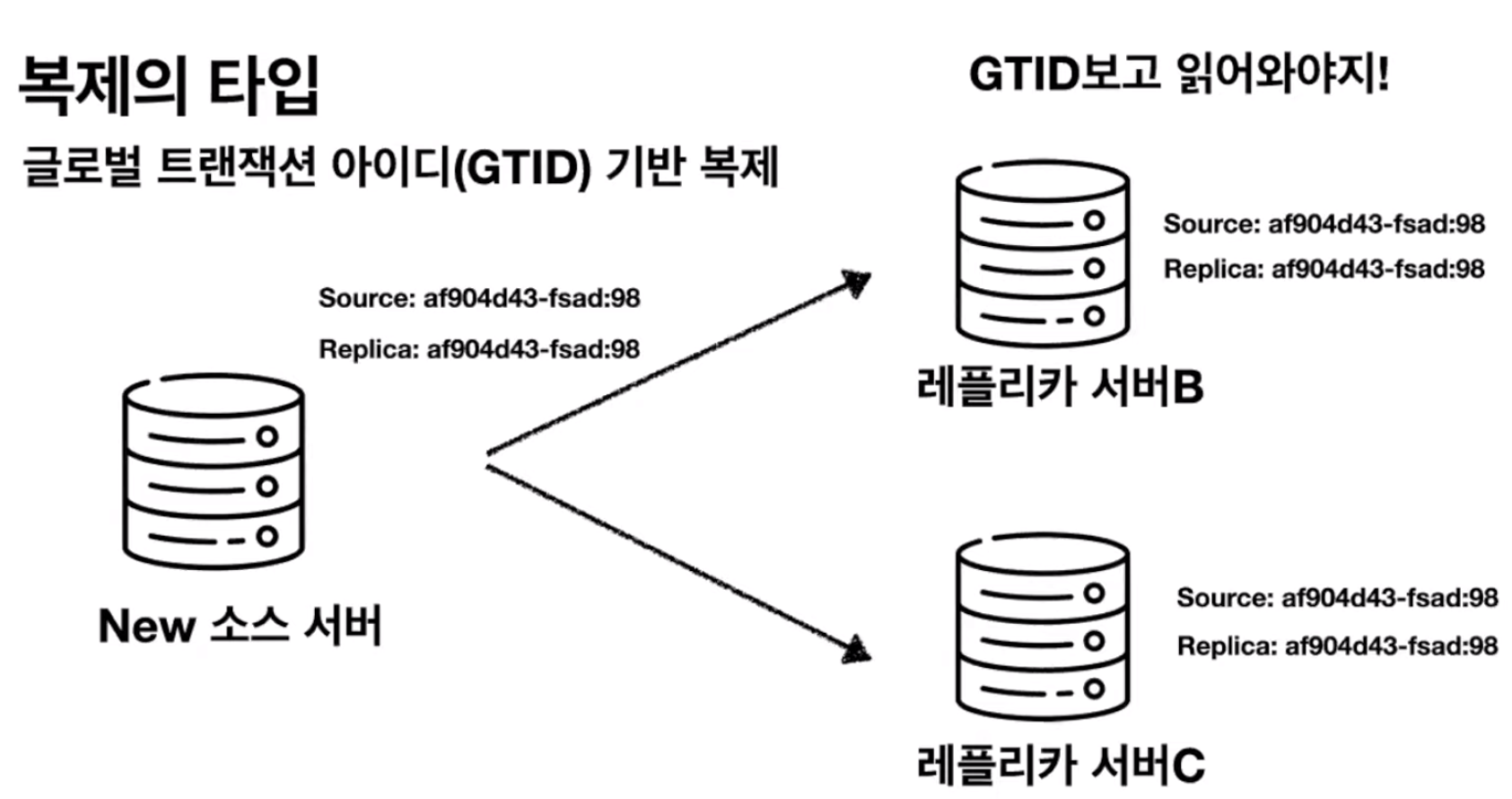
소스서버에 문제가 생겨
다른 레플리카 서버가 소스서버로 승격된 경우

이 복제에 참여하는 다른 데이터베이스 서버들은 이 위치를 다시 찾아야 하기 때문에 복구에 시간이 걸린다
즉, 동일한 이벤트가 레플리카 서버에서도 동일한 파일명의 동일한 위치에 저장된다는 보장이 없다.
그래서 MySQL 5.6버전부터는 그런 글로벌 트랜잭션 기반 복제를 기본 복제 방식으로 사용하고 있습니다.

글로벌 트랜잭션이란 복제에 참여한 모든 데이터베이스들이 고유한 식별값을 갖고 있다
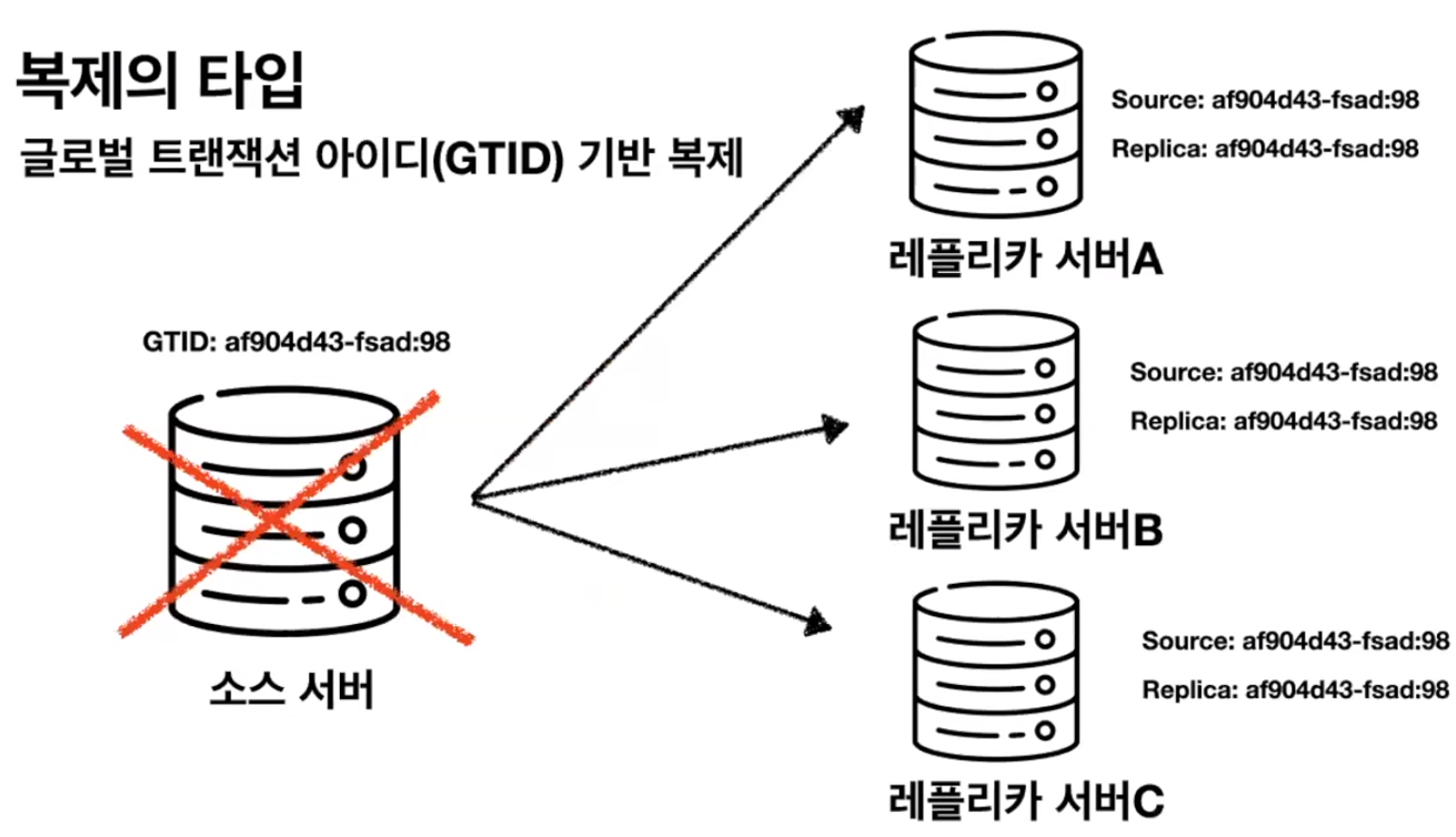
이 값은 모두 동일하기 때문에 동일한 이벤트에 대해서 동일한 글로벌 트랜잭션만 읽어보면 반영할 수 있다
---
바이너리 로그의 이벤트들은 어떤 형식으로 저장돼 있는지 = 바이너리 로그의 포맷

Statement 기반 방식
Row 기반 방식
이 둘을 합친 Mixed 기반 방식이 있다
Statement 기반 방식은

실행된 SQL문이 바이너리 로그에 그대로 저장

이런 장점
단점은

실행할 때마다 결과값이 달라지는 쿼리의 경우 데이터 동기화 문제 발생
트랜잭션 격리수준이 REPEATABLE-READ이상만 사용이 가능
= 일관되지 않은 데이터가 저장될 위험이 있다!
그래서 MySQL 5.7.7버전부터 Row기반 바이너리 로그 포맷을 기본으로 사용

이 방식은 변경 값 자체가 바이너리 로그에 그대로 저장돼 있는 형식

데이터를 많이 변경하는 SQL의 경우 바이너리 로그 파일의 크기가 거질 수 있는 단점
어떤 쿼리들이 넘어갔는지 육안으로 확인하기 어렵다는 단점
그럼에도 불구하고 이와 같은 방식은 데이터를 일관되게 저장하는 가장 안전한 방식이다!
Mixed방식은

사용자가 커스텀하는 것
기본적으로 쿼리는 Statement 포맷으로 저장하되, 비확정적 쿼리라면 Row 포맷으로 저장하는 방식을 사용할 수 있다
---
소스 서버로부터 레플리카 서버까지 복제가 잘 일어났는지 어떻게 확인할 수 있을까?

비동기 복제
반동기 복제
두가지 방식을 제공
비동기 복제 방식은

데이터 변경 요청이 들어왔을 때 바이너리 로그의 이벤트를 먼저 작성한 후, 바로 소스 서버에 스토리지 엔진에 커밋을 하게 된다. 그 이후에 변경 이벤트를 레플리카 서버로 전송한다.
이런 방식의 경우 변경 이벤트를 레플리카 서버로부터 소스서버로 확인 이벤트를 보내지 않아
->성능은 빠르지만 동기화 보장 X
그래서 MySQL 5.5버전 부터는 반동기 복제 방식을 사용하게 됨.

데이터 변경 요청이 소스 서버로 들어오면
바로 이벤트를 바이너리 로그에 기록한 후, 이 변경 이벤트를 레플리카 서버로 전송
레플리카 서버는 이 변경 이벤트를 잘 받았다는 응답을 보내게 되고, 이 응답이 오고 난 이후에 소스 서버는 변경 내역을 스토리지 엔진에 커밋한다.
▽커밋전에 복제서버에 보내는구나
이런 방식에서 레플리카 서버가 보내는 응답은 변경 이벤트를 잘 받았다는 응답이지, 이벤트가 레플리카 서버에 적용됐다는 응답을 보내는 것은 아냐
---

---
(3)
DB Replication topology
그럼 소스서버와 레플리카 서버를 어떻게 구성할 수 있을까?

먼저 소스서버 한대와 레플리카 서버를 한대 두는 싱글레플리카, 레플리카 서버는 예비 서버 및 데이터 백업용으로 활용

멀티 레플리카, 싱글 레플리카 구조에 레플리카 서버를 한대 더 둔 것.

레플리카는 두대를 사용하는데, 첫번째는 쿼리 부하 분산용, 두번째는 백업용
체인복제형식, 소스서버에 연결된 레플리카 서버가 많다면 소스서버에 복제 부하가 커지므로 다른 레플리카 서버를 소스 서버로 활용해 복제 부하를 분산시키는데 사용

또한 서버 업데이트 혹은 장비 교체 때도 이런 체인 복제 구성을 사용할 수 있다(?)


듀얼 소스 복제

트랜잭션 충돌이 일어날 경우 롤백, 복제 멈춤 현상이 일어나기 때문에 잘 사용되지 않는 토폴로지
마지막 멀티 소스 복제

레플리카 서버 한대에 소스 서버가 여러개 연결된 형태
소스서버에 흩어져 있는 데이터들을 한데 모아 데이터를 분석할 때 사용
---
(4)
복제 과정 중 문제 발생 시 회복 기법
소스서버에 장애가 난 경우 레플리카 서버를 활용하는 방법에 대해 알아봤는데,

레플리카 서버가 소스서버에 데이터를 복제할 때 문제가 생긴다면 어떻게 다시 동기화를 이뤄낼까?
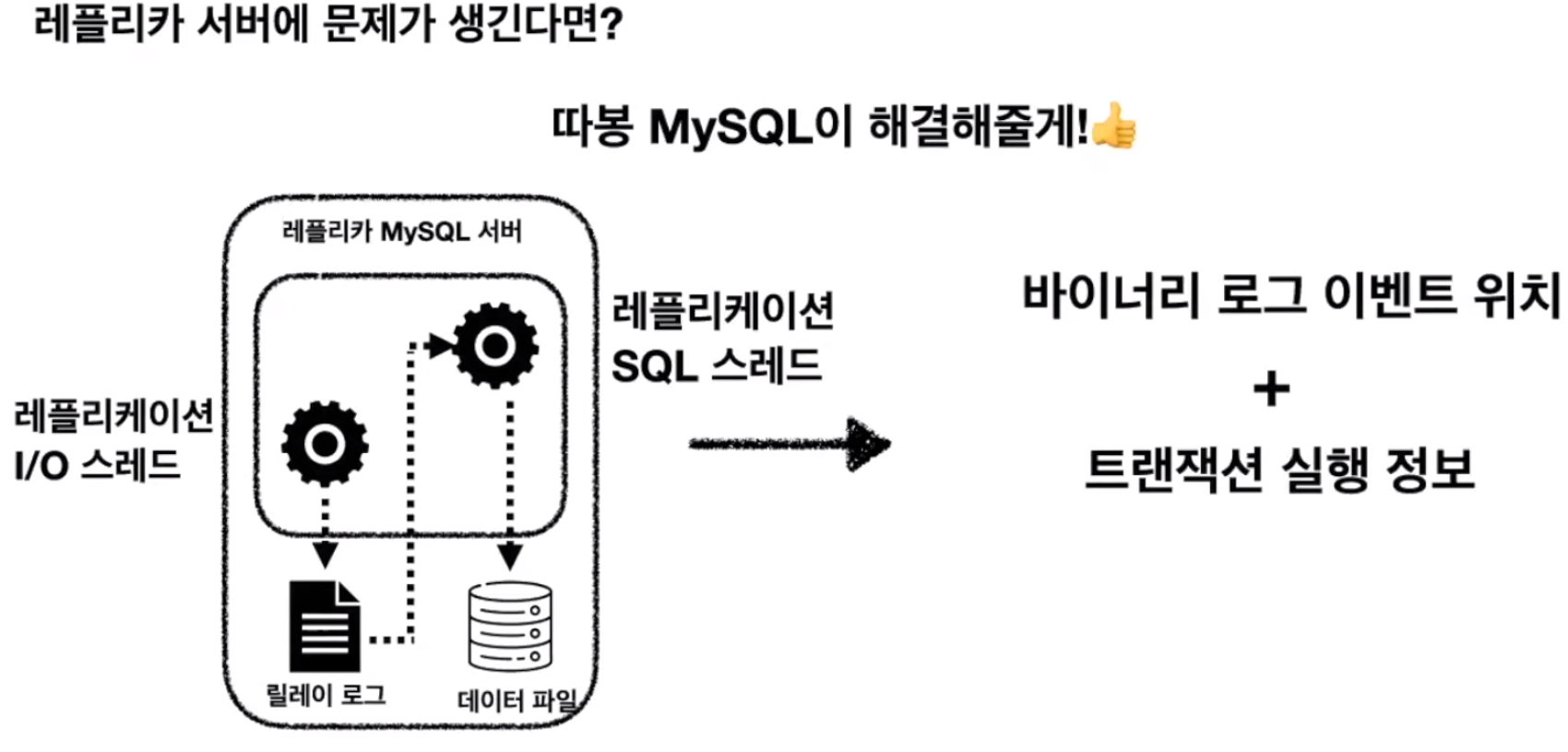
MySQL은 세이프 복제라는 방식을 제공하고 있다.
레플리카 서버는 I/O쓰레드와 SQL쓰레드를 이용해서 소스서버에 바이너리 로그 이벤트 위치를 읽을 때와 트랜잭션 실행 정보를 읽을 때 어디까지 읽었는지에 대한 포지션 정보를 로컬에 저장해 두게 됨
그 다음에 레플리카 서버에 문제가 생겨 다시 재가동했을 때 그 정보를 기반으로 다시 소스서버에 동기화를 이뤄냄
이거 말고도 다양한 복제 고급 설정을 제공

'DB > DB' 카테고리의 다른 글
[테코톡] DB Replication 3, Clustering, Sharding (0) 2023.03.10 [테코톡] DB Replication 2 (0) 2023.03.08 [테코톡] MySQL 아키텍처 2, 참고 자료, 쿼리 실행 과정, 클러스터링, MVCC, Undo log, Redo log&commit, index lock, 풀스캔PK인덱스, 복합인덱스, 더티페이지, adaptive hash index (0) 2023.02.12 [테코톡] MySQL 아키텍처 1, MySQL 엔진, plan, InnoDB 엔진, Undo log, MVCC (0) 2023.02.12 [테코톡] 트랜잭션 메커니즘, redo log, undo log (0) 2023.02.12