-
Index 쉽게, Binary Search Tree, Btree, B+tree (완)DB/DB 2023. 1. 26. 07:19
---
---
결론 :
1)인덱스는 '컬럼'을 복사해서 정렬한건데 각각 레코드에 원래 테이블의 행 주소 같은게 숨겨져 있다(이게 Non CI인가봐)
2)PK로 설정된 컬럼은 자동으로 정렬이 돼 있기 때문에 굳이 index를 만들 필요 없다. 이걸 clustered index라고 부른다
▽PK로 설정된 컬럼은 자동으로 정렬이 돼 있다는 말이 홍은채, 사쿠라, 안유진 이런 순서로 저장해도 여기에 숫자를 따로 붙이거나 그런건가
---
DB에 데이터를 많이 저장해놨어

RDB의 경우 SELECT 어쩌구 WHERE age = 20 (SQL문법)
컴퓨터는 age가 20인걸 찾으려고 모든 행을 하나씩 까본다
왜? 어딨는지 모르니까
데이터가 1억개면?
age가 20인걸 찾기 위해 1억개의 행을 전부다 확인 해본다
행이 너무 많으면 느려져
---
컴퓨터가 편하고 빠르게 데이터를 찾게 하고 싶으면 index라는걸 사용하면 된다

영어 사전에 비유하면 쉽다
일단 그렇게 생각해놓고
---

1부터 100까지의 숫자중에 아무거나 생각하게 하고 그거를 맞춰나갈 때
질문을 어떻게 하면 좋을까
1?
2?
3?
이렇게 하나하나 물어볼 수도 있지. 최악의 상황에선 100번이나 질문할 수도 있어
하지만 똑똑한 사람은 50보다 커요? 75보다 작아요? 이렇게 반씩 소거해버리면서 숫자를 찾아내면 빠르게 찾아낼 수 있다
데이터베이스안에 있는 데이터들도 이런 방법을 사용하면 절반씩 소거하면서 빠르게 원하는 데이터를 찾아낼 수 있고요
데이터가 1억개여도 2~30번 안에 찾을 수 있어
---
근데 이렇게 하고 싶으면 중요한 전제조건이 있다
카드를 다시 보면 미리 1부터 100까지 순서대로 정렬이 돼 있었잖아
미리 정렬 해놔야 절반씩 소거하며 찾을 수 있어
그래서 age컬럼에서 데이터를 빠르게 찾고 싶으면

age컬럼을 복사해서 미리 1234순으로 정렬해놓으면 됨
복사해서 정렬해둔 컬럼을 전문용어로 index!
---
인덱스를 실제로 어떻게 구현하는지, 어떻게 생겼는지
인덱스를 만들고 싶으면 컬럼안의 자료들을 복사해서 정렬해두면 끝이라고 했는데
컴퓨터 안의 자료들을 정렬하고 싶으면

이런 자료형에 담아서 정렬해도 되는데
실제 데이터베이스들은 인덱스를 만들 때 저런거 말고
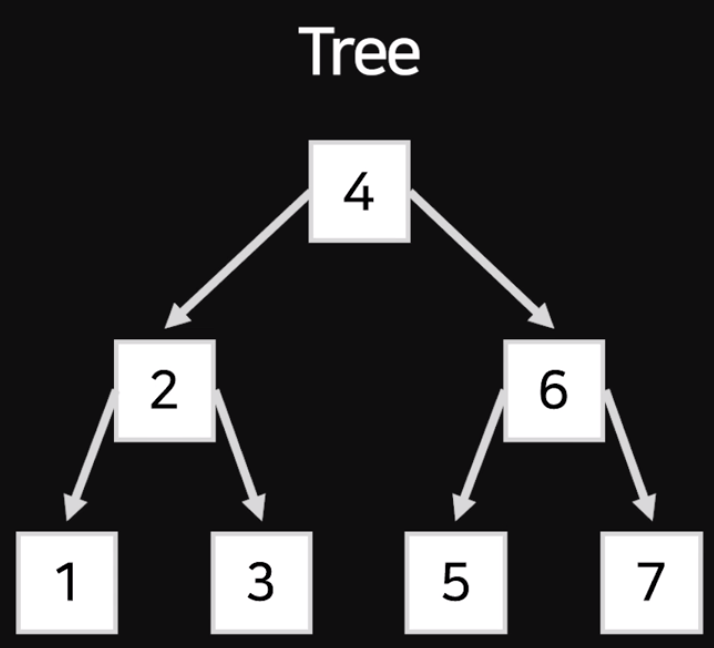
트리 형태로 배치하고 정렬해둠

이렇게 귀찮게 데이터들을 다 가져와서 일렬로 나열하고 정렬하는게 아니라
트리처럼 아무데나 흩뿌려져 있는 데이터를 화살표로 연결만 해둔다는 것. 그리고 숫자들을 왼쪽부터 정렬하면 트리 완성(이 한줄 무슨 말인지 모르겠어. 따로 찾아보면 실제로 물리적으로 정렬하지 한다는데?)
트리처럼 해놔도 반씩 갈라가면서 데이터를 찾아낼 수가 있음

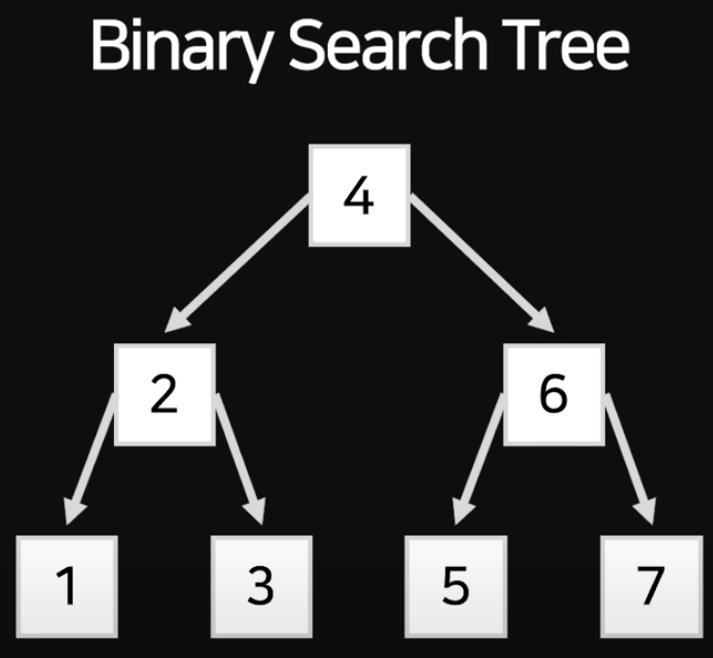
이런식으로. index는 이렇게 자료를 배치해둠. 이렇게 생긴 트리를 Binary Search Tree라고 한다
---
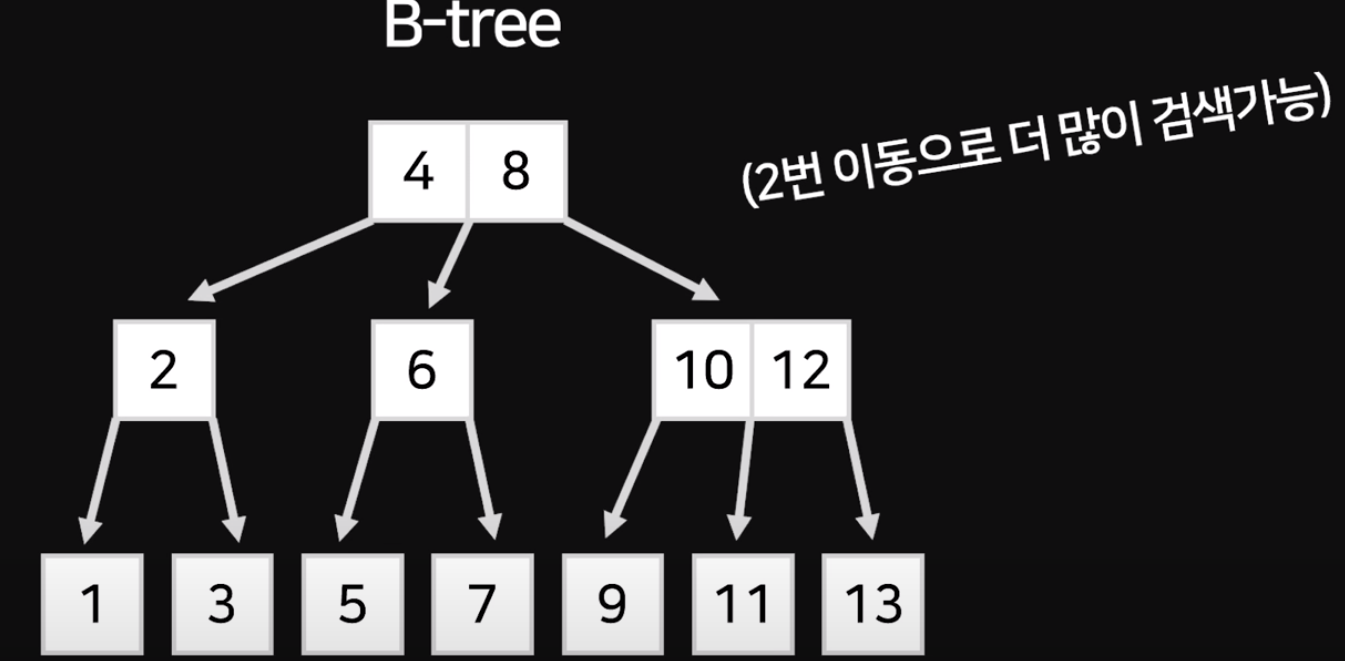
잘 보면 성능을 좀 더 개선시킬 수 있다

각각은 node라고 부르는데
node마다 데이터를 하나만 넣는게 아니라 두개세개 넣는 것

그러면 반이 아니라 3/1씩 4/1씩 자를 수 있어. 이걸 있어보이는 말로 B-tree라고 한다

아까는 2번 이동으로 (최대?) 1~7까지 검색 가능

지금은 (2번이동으로 최대?) 1~13
---
한번 더 업그레이드 할 수도 있어
실제 데이터베이스들은 Btree말고 B+tree라는 형태로 데이터를 보관하는 경우가 많다
데이터를 노드마다 보관하는게 아니라 가장 아래 노드에만 보관해두는 것
위에 있는 노드들엔 데이터말고 데이터 탐색 가이드라인 같은것만 제공

애의 다른 점은 맨 아래 노드끼리도 화살표로 연결이 가능

이러면 범위 검색이 매우 쉬워진다
4~8까지의 데이터를 찾고 싶으면 ▽age만 4~8이고 거기 안에 레코드는 따로 있는거군?포인터든지

Btree에선 위아래 왔다갔다 해야돼
B+tree에선

4부터 찾은 화살표 타고 다음 노드로 이동만 하면 끝. 컴퓨터도 빨리 수행할 수 있어
요즘 데이터베이스는 B+tree로 index를 만들어주는 경우가 많다
---
인덱스가 있을 때와 없을 때 검색이 어떻게 달라지는지
없을 땐 테이블 전체 풀스캔
인덱스가 있을 땐 자동으로 index부터 들여다본다. 몇번 탐색만에 빠르게 찾아주고
인덱스에서 찾은 데이터 안에는 원래 테이블의 행 주소같은게 숨겨져 있어. 그걸 타고 들어가서 출력

---
단점
이제 단점도 보인다.
단점 1.인덱스 만들어두면 컬럼을 복사해서 정렬해두는 개념이라 만들때마다 DB용량을 차지한다

그래서 검색 작업이 필요없는 그런 컬럼들은 굳이 인덱스를 만들어둘 필요없다
단점 2.기존 테이블에 있던 데이터를 삽입 수정 삭제 해버리면

index에도 똑같이 반영해줘야해. index안에 있던 데이터순서들이 바뀌어야해.
데이터를 수정삭제하는 작업이 추가로 들어가야해서 성능하락같은게 있을 수 있다. 근데 실은 크게 신경쓸 필요없대
---

PK로 설정된 컬럼은 자동으로 정렬이 돼 있기 때문에 굳이 index를 만들 필요 없다. 이걸 clustered index라고 부른다
---
댓글
그럼 디비 용량이 엄청 넉넉하고 거의 모든 컬럼을 검색키로 하는 레코드가 엄청많은 테이블의 경우에는 인덱스를 프라이머리키 제외한 모든 컬럼에 만들어도 상관없을까요??
index를 만능키로 생각하면 경우에 따라 위험할 수도 있습니다. 데이터가 많은데 모든 컬럼에 index를 걸어둔 채 insert, update, delete 가 자주 일어나는 상황이면 db 장비의 리소스를 잡아먹어서 예상치 못한 문제가 발생합니다. 서버 이전이나 db 롤백같은 작업이 필요할 때 테이블 하나가 너무 크면 할당된 작업 시간 내에는 답이 없는 경우도 종종 있습니다. 아무리 index가 잘 걸려있어도 데이터가 많아지면 select 도 느려질 수 있습니다. 모든 데이터가 균일한 검색 빈도를 가지는 것이 아니면.. 예를 들면 오래 된 데이터는 검색 요청이 잘 없다면 분리가 가능하죠. 테이블 하나로 설계할 것이 아니라 연관있는 항목끼리 잘 묶어서 여러 테이블로 분산할 수 있는지 고민해 볼 수 있습니다.
레코드가 정말 너무 많으면 테이블을 여러 개 쓰는 것도 추천합니다. app 에서 미리 계산하여 table을 찾은 뒤 검색하면 되므로 db 부하를 줄일 수 있습니다 시스템 환경에 따라 적절하게 db 설계를 하고, 타협선을 찾아 app 에서 부하를 나눠서 가져가는 것이 현명합니다.
실제 쓸 땐 where에 단 하나 칼럼만 넣는 게 아니고 and도 넣고 이것저것 할텐데 컴포지트 인덱스 같은 복수 컬럼 인덱스가 필요해지고, 그 땐 인덱스 순서 탓에 있어도 못 써먹기도 합니다. 계획 잘 세우고 해야지 쓸데없는 인덱스 만들면 insert update 느려지고 디비 용량도 크고 나중에 데이터 개수 늘면 인덱스 변경도 몇 시간짜리 작업이 되어서 바로잡으려고 해도 손쓸 수 없게 됩니다.
---
댓글2
인덱스를 따로 만들기만하면 똑같은 명령 select * where age=20 을해도 적용이된다는건가요??
DB가 SQL 문을 수행하기전에 내부에서 최적화를 하게 됩니다. 즉 인덱스가 존재한다면 그를 활용하는 방식으로 실행계획이 수립되게 된다는 거죠. 자세한 내용은 실행계획 및 데이터베이스 옵티마이저 검색 ㄱㄱ
MySQL이나 MariaDB라면 select 문 앞에 explain 스페이바만 붙여서 같은 쿼리가 어떻게 달라지는지, 인덱스 추가 후 경우와 인덱스 지운 후 경우를 비교해보세요. FULLSCAN이라는 글자를 보는 순간 이건 웹에 공개하면, 줄 수가 늘어날 수록 엄청나게 쿼리가 느리겠구나 인덱스가 그래서 중요하구나 감이 잡히실 겁니다.
'DB > DB' 카테고리의 다른 글
cm-db (3-2)복제 (0) 2023.02.03 cm-db (3-1)SQL 실행 과정, Architecture, tablespace (0) 2023.02.03 cm-db (2)설치, 라이센스, 공식 문서, 프롬프트, 샘플데이터, 원격지, 파라미터 (0) 2023.01.10 cm-db (1)DML, DDL, DCL, 트랜잭션, ACID, 아키텍처, MVCC, TableSpace (0) 2023.01.10 정미나 > 데이터 분석 > 데이터 관련 용어 설명해드림 (0) 2023.01.08